These are some of my takeaways from the Batch Normalization paper by
Ioffe and Szegedy. You can find it here on Arxiv.
This is in no way a description or explanation of batch normalization.
If you don't know what it is or want to understand it thoroughly, the
paper is a good place to start.
Why batch norm speeds up learning with any activation not just sigmoid?
It shouldn't be hard to see why batch norm works well with functions
like sigmoid or tanh.
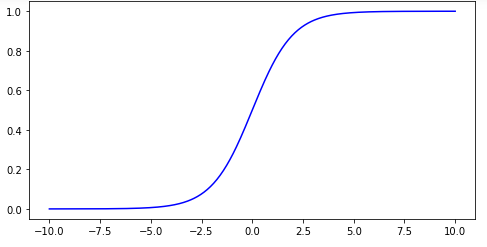
When you look at a graph of sigmoid it is very flat for large values of x.
The sigmoid activation function
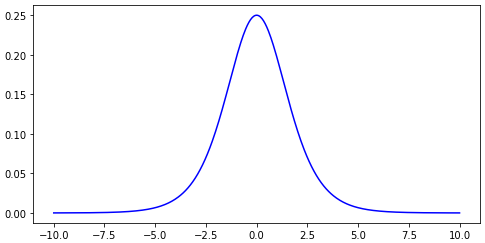
and therefore the derivative is also close to zero and any learning is then very slow.
The derivative of sigmoid
Any flow of information can then easily vanish especially if the network is deep.
Here, the batch norm is helpful because it tries to stop the network from ever reaching
those extreme points.
However, it's not that clear why some kind of normalization should help
us with other activation functions which doen't have a similar saturation problem.
Although the paper doesn't state it directly, the part on the covariate shift gives
an intuition on why the batch norm is great with any activation function.
A general problem with deep nets is that any change in an early layer can propagate
and changes in layers can interfere in hard-to-predict ways.
Therefore, for very deep layers it happens that their inputs (outputs of the
previous layers) change a lot.
Batch norm makes this thing a lot less damaging because it ensures that
outputs of each layer are centered and shifted to have variance 1.
Subsequently, the batch norm speeds up training because it makes the network
more stable.
Bias
Bias is not needed with the batch norm for two reasons.
It is canceled by the mean subtraction
It is subsumed by β in the equation for BN output y=γx^+β.
Why it acts as a regularizer?
In the paper it is stated that batch norm has a good regularization
effect and maybe even dropout can be dropped when using BN.
I don't think that the regularization effect is that strong, nonetheless it is
quite nice to see from where it comes.
Batch norm calculates the mean and variance from the minibatch.
Ideally, whenever the net sees a particular training sample it comes
with different comrades in the batch.
Therefore, the mean and variance are a little bit different.
This adds some unpredictability and noise to the training which results
in a bit of regularization.
Learning rates
It might be a good idea to try increasing the learning rate when using
batch norm.
Because it stabilizes the training phase it helps prevent gradients from
exploding or vanishing.
Batch norm and GELU
This is not from the batch norm paper but the GELU one.
In it it is claimed that batch norm should ensure gaussian-like distribution
of neuron activations which is generally good for GELU.